In the previous tutorial we run our first model and we checked whether the model met the assumptions. You have to agree it was easy and fun! Now the real challenge begins.
df=read.csv("..\\..\\resources\\Stats\\LM_SimulatedData.csv")mod=lm(performance~time*tool, data =df)
Interpreting the results
Very cool!! we have our result!!
But what is it saying?? As you can see the summary is divided in subsections. Lets go trough them piece by piece.
Call:
This section just report the function call that we passed to lm().
Residuals:
This section reports the residuals of the model. Residuals represent the difference between the observed values and the values predicted by the model. Essentially, how much variability remains after fitting our variable to the model.
Coefficients:
This section displays the estimated coefficients of the regression model,the stand error of the estimation, the t-value and finally the p-value!
Model Fit:
The last section reports different statistics about the model fit:
Residual standard error: Average distance between observed values and the regression line. Smaller is better.
Multiple R-Squared: Proportion of response variable variance explained by predictors. Ranges from 0 to 1; closer to 1 is better.
Adjusted R-squared: R-squared modified for the number of predictors. Useful for comparing models with different numbers of predictors.
F-statistic and p-value: Indicate if the model provides a better fit than a model with no predictors. A p-value < 0.05 suggests the model is useful.
Coeffiecients
The Coefficient section if indubitably the most important section of the summary of our model. However what are all these numbers? Let’s go together through the most challenging information:
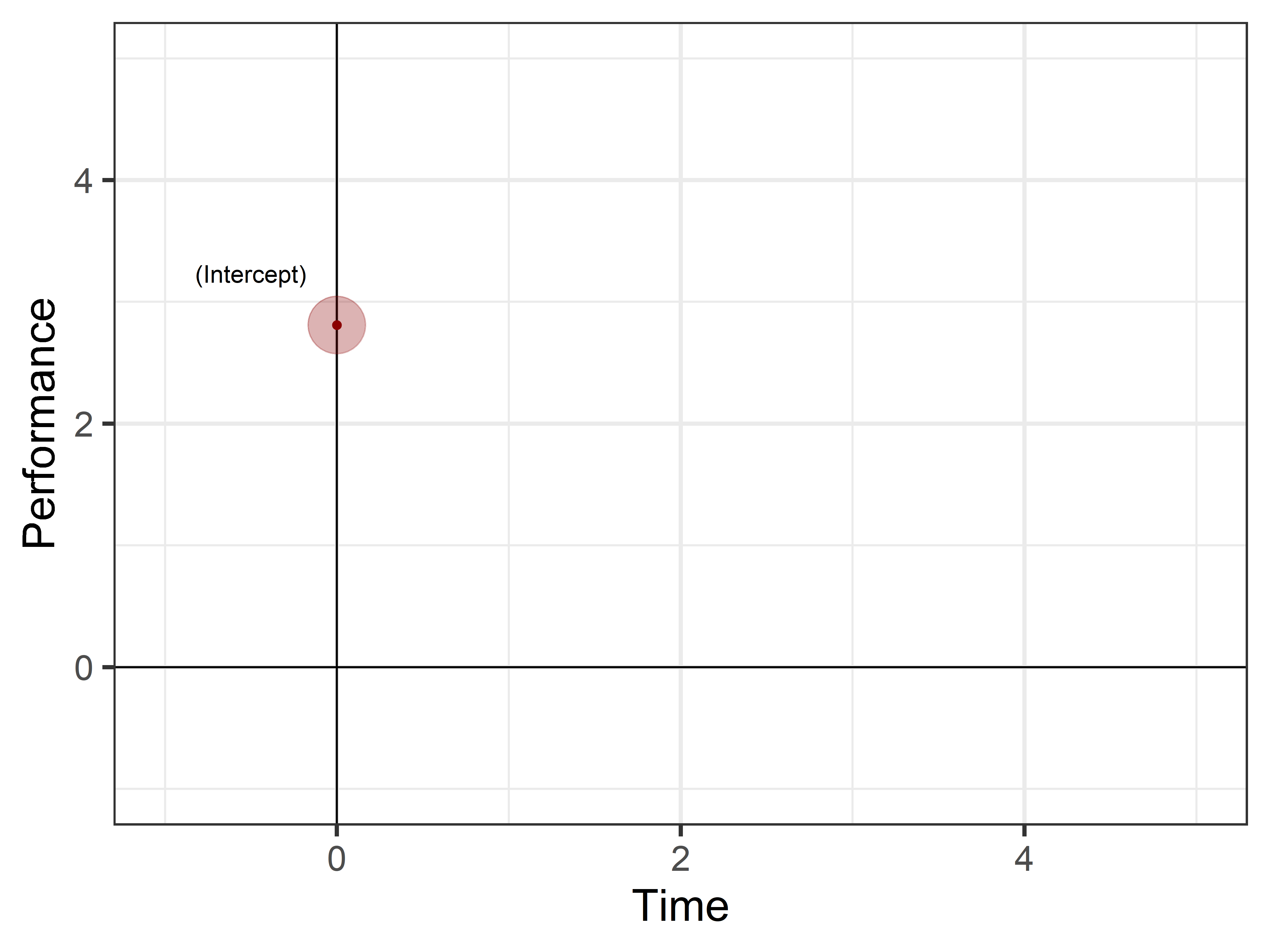
(Intercept)
The intercept often confuses who approaches for the first time linear models. What is it? The (Intercept) represent the reference levels where all our predictors (time and tool) are 0. Now you may ask…how can tool be 0? It is a categorical variable, it can’t be 0!!!!
You are correct. When a model encounters a categorical variable it selects the first level of such variable as reference level. If you take another look to our model summary you can see that there are information both for the hammerand spoon level of the toolvariable but nothing about the brush level. This is because the brush level has been selected by the model as the reference level and it is thus represented in the intercept value!
we can simply visualize it as:
library(ggplot2)model_p=parameters(mod)# Define intercept and slope for the brushintercept_brush<-model_p[1,2]intercept_brush_se<-model_p[1,3]# To create estimatestime_values<-seq(0, 10, by =0.5)ggplot()+# Cartesian linesgeom_vline(xintercept =0)+geom_hline(yintercept =0)+# Interceptannotate("point", x =0, y =intercept_brush, size =pi*intercept_brush_se^2, alpha =0.3, color ='darkred')+annotate("point", x =0, y =intercept_brush, color ='darkred')+annotate("text", x =-0.5, y=intercept_brush*1.15, label='(Intercept)')+# Plot addition informationcoord_cartesian(xlim =c(-1,5), ylim =c(-1,5))+labs(y ='Performance', x ='Time')+theme_bw(base_size =20)
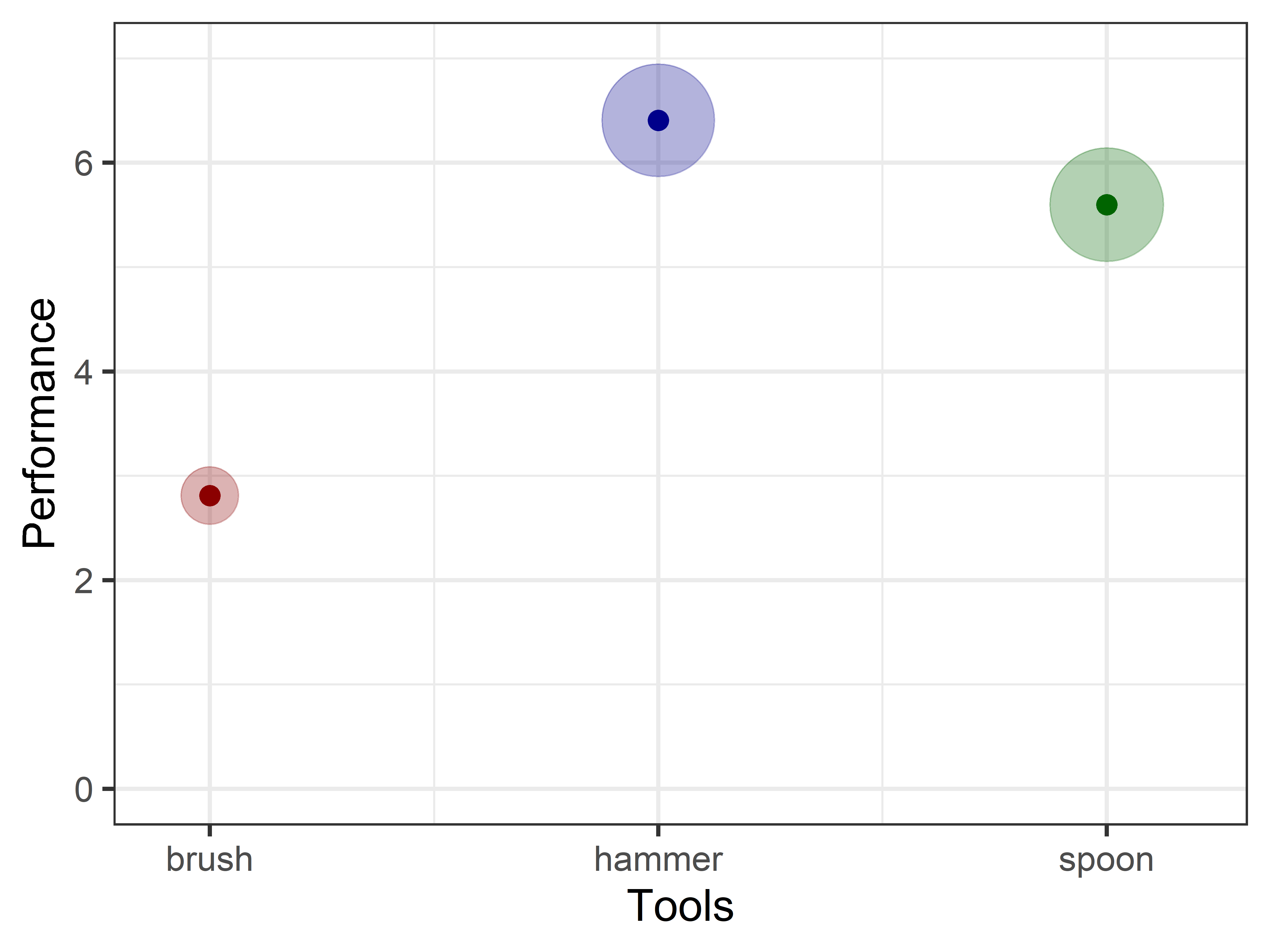
Tools
# Define intercept and slope for the brushintercept_brush<-model_p[1,2]intercept_brush_se<-model_p[1,3]intercept_hammer<-model_p[3,2]+intercept_brushintercept_hammer_se<-model_p[3,3]intercept_spoon<-model_p[4,2]+intercept_brushintercept_spoon_se<-model_p[4,3]ggplot()+# Intercept (brush)annotate("point", x =0, y =intercept_brush, size =pi*intercept_brush_se^2, alpha =0.3, color ='darkred')+annotate("point", x =0, y =intercept_brush, color ='darkred', size =4)+# Hammerannotate("point", x =1, y =intercept_hammer, size =pi*intercept_hammer_se^2, alpha =0.3, color ='darkblue')+annotate("point", x =1, y =intercept_hammer, color ='darkblue', size =4)+# Spoonannotate("point", x =2, y =intercept_spoon, size =pi*intercept_spoon_se^2, alpha =0.3, color ='darkgreen')+annotate("point", x =2, y =intercept_spoon, color ='darkgreen', size =4)+# Set the limits for x and y axescoord_cartesian(xlim =c(-0.1, 2.2), ylim =c(0, 7))+# Customize x-axis breaksscale_x_continuous(breaks =c(0, 1, 2), labels =c('brush','hammer','spoon'))+# Labels and themelabs(y ='Performance', x ='Tools')+theme_bw(base_size =20)
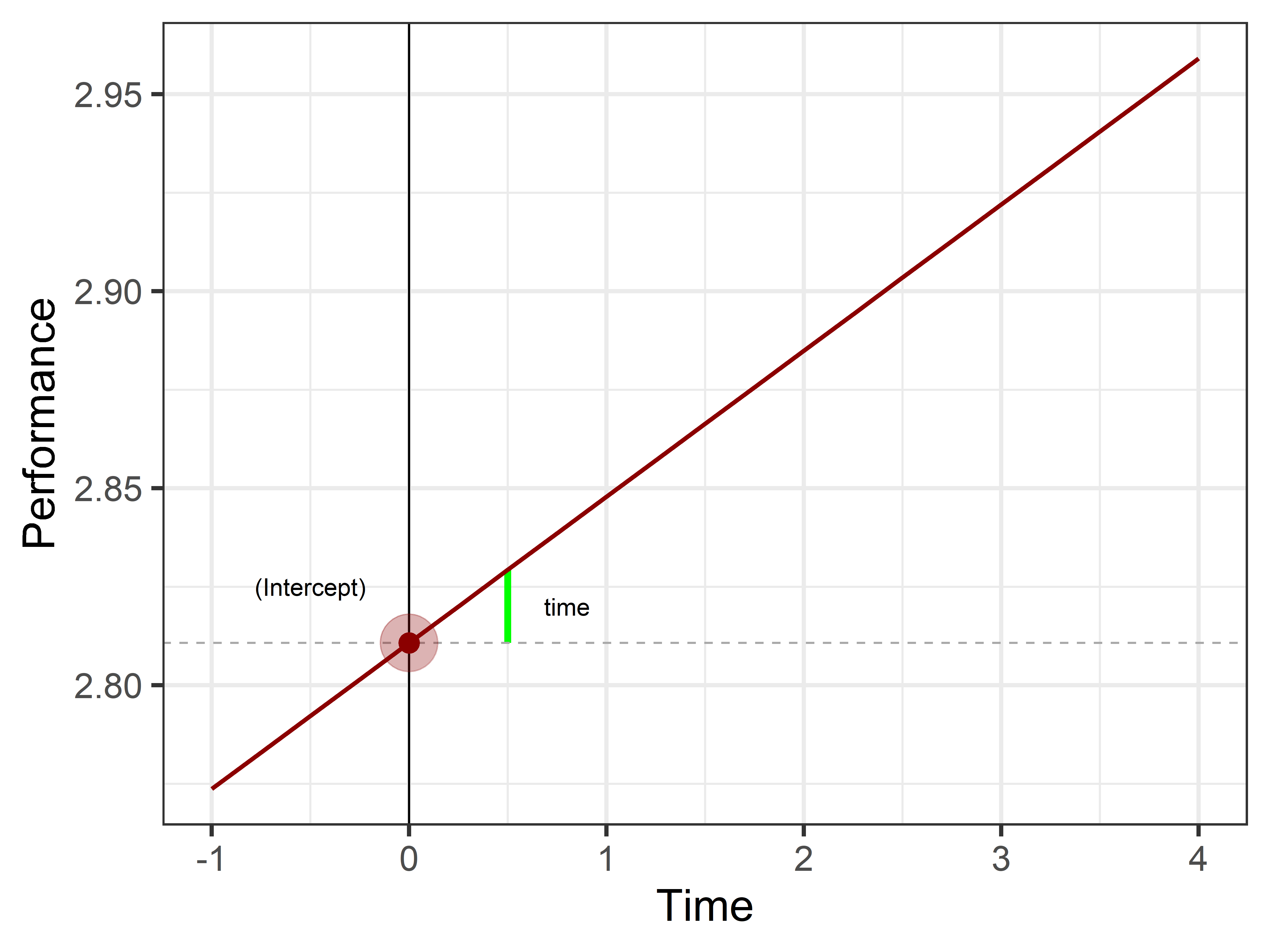
Time
The estimates are the slopes (the inclination) of the lines of each predictor. However they should be interpreted as a difference from the intercept.
# Define intercept and slope for the brushintercept_brush<-model_p[1,2]intercept_brush_se<-model_p[1,3]slope_brush<-model_p[2,2]slope_brush_se<-model_p[2,3]# To create estimatestime_values<-seq(-1, 4, by =0.25)# Create a data framedf_brush<-data.frame(time =time_values, est_performance =intercept_brush+slope_brush*time_values)# Function to create an arc between two angles with a custom centergenerate_circle_piece<-function(center=c(0, 0), radius=1, start_angle=0, end_angle=90){# Convert angles to radiansstart_rad<-start_angle*pi/180end_rad<-end_angle*pi/180# Generate points for the piece of the circletheta<-seq(start_rad, end_rad, length.out =100)x<-center[1]+radius*cos(theta)y<-center[2]+radius*sin(theta)# Create a data frame for the circle pointscircle_data<-data.frame(x =x, y =y)return(circle_data)}# Create data for the arc with the angle calculated from the slope, using the new centerarc_data<-generate_circle_piece(center =c(0, intercept_brush), radius =0.5, start_angle =0, end_angle =atan(slope_brush)*(180/pi))ggplot(df_brush, aes(x =time, y =est_performance))+# Cartesian linesgeom_vline(xintercept =0)+# geom_hline(yintercept = 0)+# # Timegeom_path(data =arc_data, aes(x =x, y =y), color ='green', size =1.5)+geom_hline(yintercept =intercept_brush, linetype ='dashed', color ='darkgray')+geom_line(color ="darkred", size =1)+# Interceptannotate("point", x =0, y =intercept_brush, size =pi*intercept_brush_se^2, alpha =0.3, color ='darkred')+annotate("point", x =0, y =intercept_brush, color ='darkred', size =4)+# Textannotate("text", x =-0.5, y=2.825, label='(Intercept)')+annotate("text", x =0.8, y=2.82, label='time')+# Plot addition information# coord_cartesian(xlim = c(-1,4), ylim = c(-1,5))+labs(y ='Performance', x ='Time')+theme_bw(base_size =20)
---title: "Interpreting Model Results"author: "Tommaso Ghilardi"author-meta: "Tommaso Ghilardi"execute: eval: truedescription-meta: "Learn what a the summary of a linear model means!"keywords-meta: "R, lm, Linear models, statistics, analysis, psychology, tutorial, experiment, DevStart, developmental science"drafts: Truedraft-mode: unlinked---In the previous tutorial we run our first model and we checked whether the model met the assumptions. You have to agree it was easy and fun! Now the real challenge begins.```{r}library(tidyverse)library(easystats)df =read.csv("..\\..\\resources\\Stats\\LM_SimulatedData.csv")mod =lm(performance ~ time*tool, data = df)```# Interpreting the resultsVery cool!! we have our result!!But what is it saying?? As you can see the summary is divided in subsections. Lets go trough them piece by piece.- **Call**: This section just report the function call that we passed to `lm()`.- **Residuals**: This section reports the residuals of the model. Residuals represent the difference between the observed values and the values predicted by the model. Essentially, how much variability remains after fitting our variable to the model.- **Coefficients**: This section displays the estimated coefficients of the regression model,the stand error of the estimation, the t-value and finally the p-value!- **Model Fit:** The last section reports different statistics about the model fit: - **Residual standard error:** Average distance between observed values and the regression line. Smaller is better. - **Multiple R-Squared:** Proportion of response variable variance explained by predictors. Ranges from 0 to 1; closer to 1 is better. - **Adjusted R-squared:** R-squared modified for the number of predictors. Useful for comparing models with different numbers of predictors. - **F-statistic and p-value:** Indicate if the model provides a better fit than a model with no predictors. A p-value \< 0.05 suggests the model is useful.## CoeffiecientsThe Coefficient section if indubitably the most important section of the summary of our model. However what are all these numbers? Let's go together through the most challenging information:### (Intercept)The intercept often confuses who approaches for the first time linear models. What is it? The (Intercept) represent the reference levels where all our predictors (`time` and `tool`) are 0. Now you may ask...how can `tool` be 0? It is a categorical variable, it can't be 0!!!!You are correct. When a model encounters a categorical variable it selects the first level of such variable as reference level. If you take another look to our model summary you can see that there are information both for the `hammer`and `spoon` level of the `tool`variable but nothing about the `brush` level. This is because the `brush` level has been selected by the model as the reference level and it is thus represented in the intercept value!we can simply visualize it as:\```{r}#| fig-height: 6#| fig-width: 8#| fig-dpi: 300#| warning: falselibrary(ggplot2)model_p =parameters(mod)# Define intercept and slope for the brushintercept_brush <- model_p[1,2]intercept_brush_se <- model_p[1,3]# To create estimatestime_values <-seq(0, 10, by =0.5)ggplot()+# Cartesian linesgeom_vline(xintercept =0)+geom_hline(yintercept =0)+# Interceptannotate("point", x =0, y = intercept_brush, size = pi * intercept_brush_se^2, alpha =0.3, color ='darkred') +annotate("point", x =0, y = intercept_brush, color ='darkred') +annotate("text", x =-0.5, y=intercept_brush*1.15, label='(Intercept)')+# Plot addition informationcoord_cartesian(xlim =c(-1,5), ylim =c(-1,5))+labs(y ='Performance', x ='Time')+theme_bw(base_size =20)```## Tools```{r}#| fig-height: 6#| fig-width: 8#| fig-dpi: 300#| warning: false# Define intercept and slope for the brushintercept_brush <- model_p[1,2]intercept_brush_se <- model_p[1,3]intercept_hammer <- model_p[3,2] + intercept_brushintercept_hammer_se <- model_p[3,3]intercept_spoon <- model_p[4,2]+ intercept_brushintercept_spoon_se <- model_p[4,3]ggplot() +# Intercept (brush)annotate("point", x =0, y = intercept_brush, size = pi * intercept_brush_se^2, alpha =0.3, color ='darkred') +annotate("point", x =0, y = intercept_brush, color ='darkred', size =4) +# Hammerannotate("point", x =1, y = intercept_hammer, size = pi * intercept_hammer_se^2, alpha =0.3, color ='darkblue') +annotate("point", x =1, y = intercept_hammer, color ='darkblue', size =4) +# Spoonannotate("point", x =2, y = intercept_spoon, size = pi * intercept_spoon_se^2, alpha =0.3, color ='darkgreen') +annotate("point", x =2, y = intercept_spoon, color ='darkgreen', size =4) +# Set the limits for x and y axescoord_cartesian(xlim =c(-0.1, 2.2), ylim =c(0, 7)) +# Customize x-axis breaksscale_x_continuous(breaks =c(0, 1, 2), labels =c('brush','hammer','spoon')) +# Labels and themelabs(y ='Performance', x ='Tools') +theme_bw(base_size =20)```### TimeThe estimates are the slopes (the inclination) of the lines of each predictor. However they should be interpreted as a difference from the intercept.```{r}#| fig-height: 6#| fig-width: 8#| fig-dpi: 300#| warning: false# Define intercept and slope for the brushintercept_brush <- model_p[1,2]intercept_brush_se <- model_p[1,3]slope_brush <- model_p[2,2]slope_brush_se <- model_p[2,3]# To create estimatestime_values <-seq(-1, 4, by =0.25)# Create a data framedf_brush <-data.frame(time = time_values,est_performance = intercept_brush + slope_brush * time_values)# Function to create an arc between two angles with a custom centergenerate_circle_piece <-function(center =c(0, 0), radius =1, start_angle =0, end_angle =90) {# Convert angles to radians start_rad <- start_angle * pi /180 end_rad <- end_angle * pi /180# Generate points for the piece of the circle theta <-seq(start_rad, end_rad, length.out =100) x <- center[1] + radius *cos(theta) y <- center[2] + radius *sin(theta)# Create a data frame for the circle points circle_data <-data.frame(x = x, y = y)return(circle_data)}# Create data for the arc with the angle calculated from the slope, using the new centerarc_data <-generate_circle_piece(center =c(0, intercept_brush), radius =0.5, start_angle =0, end_angle =atan(slope_brush) * (180/ pi))ggplot(df_brush, aes(x = time, y = est_performance))+# Cartesian linesgeom_vline(xintercept =0)+# geom_hline(yintercept = 0)+# # Timegeom_path(data = arc_data, aes(x = x, y = y), color ='green', size =1.5) +geom_hline(yintercept = intercept_brush, linetype ='dashed', color ='darkgray')+geom_line(color ="darkred", size =1) +# Interceptannotate("point", x =0, y = intercept_brush, size = pi * intercept_brush_se^2, alpha =0.3, color ='darkred') +annotate("point", x =0, y = intercept_brush, color ='darkred', size =4) +# Textannotate("text", x =-0.5, y=2.825, label='(Intercept)')+annotate("text", x =0.8, y=2.82, label='time')+# Plot addition information# coord_cartesian(xlim = c(-1,4), ylim = c(-1,5))+labs(y ='Performance', x ='Time')+theme_bw(base_size =20)```