If you have collected and pre-processed your pupil data, the long awaited moment arrived: It’s finally time to analyse your data and get your results!!!
In this tutorial we will do two types of analysis. The first one is more simple, and the second is more advanced. For some research questions, simple analyses are enough: they are intuitive and easy to understand. However, pupil data is actually very rich and complex, and more sophisticated analyses can sometimes help to really get the most out of your data and let them shine!
Note
We’re currently working on a tutorial about linear mixed-effect models, but it’s not ready yet! If you’re new to statistical analyses, we highly recommend this tutorial: Introduction to linear mixed models. While it doesn’t focus on pupil data specifically, it covers all the essential basics that won’t be addressed here and can be incredibly helpful.
Before starting any type of analysis, let’s import the data and take a quick look at it.
Import data
The data used in this tutorial comes from the pre-processing tutorial of pupil dilation. If you haven’t run that tutorial yet, it’s a good idea to check it out first to ensure your data is prepared and ready for analysis: Pre-processing pupil data. In case you did not save the result of the pre-processing you can download them from here :
Now that you have the data, let’s import it along with the necessary libraries. We’ll also ensure that the Event and Subjects columns are properly set as factors (categorical for easier analysis. Here’s how:
library(tidyverse)# Data manipulation and visualizationlibrary(easystats)# Easy statistical modelingdata=read.csv("..\\..\\resources\\Pupillometry\\Processed\\Processed_PupilData.csv")# Make sure Event and Subject are factorsdata$Event=as.factor(data$Event)data$Subject=as.factor(data$Subject)head(data)
For a detailed description of the data, you can have a look at the tutorial on preprocessing pupil data. The key variables to focus on here are the following:
mean_pupil indicates what the pupil size was at every moment in time (every 50 milliseconds, 20Hz). This is our dependent variable.
time indicates the specific moment in time within each trial
TrialN indicates the trial number
Event indicates whether the trial contained a circle (followed by a reward) or a square (not followed by a reward). This variable is not numerical, but categorical. We thus set it to factor with as.factor().
Subject contains a different ID number for each subject. This is also a categorical variable.
Comparing means
In many paradigms, you have two or more conditions and want to test whether your dependent variable (pupil size in this case!) is significantly different across conditions. In our example paradigm, we may want to test whether, on average, pupil size while looking at the rewarding cue (the circle) is greater than pupil size while looking at the non-rewarding cue (the square). This would mean that even before the reward is presented, infants have learned that a reward will be coming and dilate their pupils in response to it! Pretty cool, uh?
If we want to test multiple groups, we can use a t-test, an ANOVA or… A linear model! Here, we’ll be using a special type of linear model, a mixed-effect model - which is infinitely better for many many reasons [add link].
Adapt the data
We want to compare the means across conditions but… We don’t have means yet! We have a much richer dataset, that contains hundreds of datapoints with milliseconds precision. For this first simple analysis, we just want one average measure of pupil dilation for each trial instead. We can compute this using the tidyverse library (that is container of multiple packages) a powerful collection of packages for wrangling and visualuzating dataframes in R.
Here, we group the data by Subject, Event, and TrialN, then summarize it within these groups by calculating the mean values.
# A tibble: 6 × 4
# Groups: Subject, Event [2]
Subject Event TrialN mean_pupil
<fct> <fct> <int> <dbl>
1 Subject_1 Circle 3 0.0397
2 Subject_1 Circle 4 0.281
3 Subject_1 Circle 6 0.0559
4 Subject_1 Circle 9 -0.0393
5 Subject_1 Square 2 -0.139
6 Subject_1 Square 5 0.0420
Important
In this step, we used the average to calculate an index for each trial, meaning we averaged the pupil dilation over the trial duration. However, this is not the only option. Other approaches include extracting the peak value (max(mean_pupil, na.rm = TRUE)) or calculating the sum of the signal (sum(mean_pupil, na.rm = TRUE)), which can also represent the area under the curve (AUC) for the trial.
Linear mixed-effects model
With a single value for each participant, condition, and trial (averaged across time points), we are now ready to proceed with our analysis. Even if the word “Linear mixed-effect model” might sound scary, the model is actually very simple. We take our experimental conditions (Event) and check whether they affect pupil size (mean_pupil). To account for individual differences in pupil response intensity, we include participants as a random intercept.
Let’s give it a go!!!
library(lmerTest)# Mixed-effect models library# The actual modelmodel_avg=lmer(mean_pupil~Event+(1|Subject), data =averaged_data)summary(model_avg)# summary of the model
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: mean_pupil ~ Event + (1 | Subject)
Data: averaged_data
REML criterion at convergence: 17.3
Scaled residuals:
Min 1Q Median 3Q Max
-1.84767 -0.66407 0.02253 0.65595 2.02017
Random effects:
Groups Name Variance Std.Dev.
Subject (Intercept) 0.0008353 0.0289
Residual 0.0709333 0.2663
Number of obs: 55, groups: Subject, 6
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.10770 0.05263 17.80244 2.046 0.0558 .
EventSquare -0.20781 0.07186 48.97131 -2.892 0.0057 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
EventSquare -0.695
Tip
We won’t dive into the detailed interpretation of the results here—this isn’t the right place for that. However, if you are not familiar with linear mixed-effects models you can check our introduction of Linear models and Linear mixed-effects models where we try to break everything down step by step!
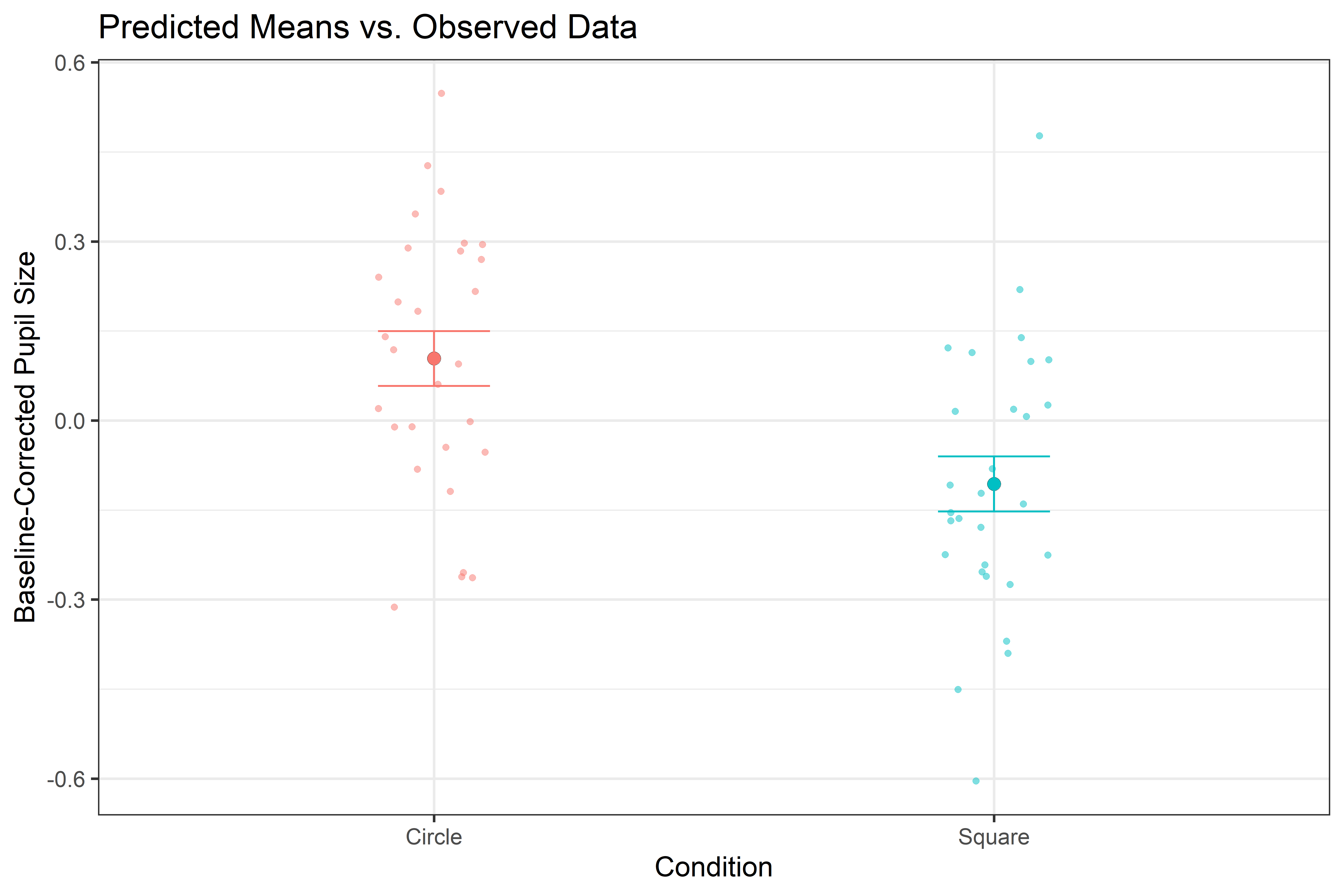
The key takeaway here is that there’s a significatn difference between the Event. Specifically, the Square cue appears to result in smaller pupil dilation compared to the Circle event (which serves as the reference level for the intercept). COOL!
Let’s visualize the effect!!
Code
# Create a data grid for Event and timedatagrid=get_datagrid(model_avg, by =c('Event'))# Compute model-based expected values for each level of Eventpred=estimate_expectation(datagrid)# 'pred' now contains predicted values and confidence intervals for each event condition.# We can visualize these predictions and overlay them on the observed data.ggplot()+# Observed data (jittered points to show distribution)geom_jitter(data =averaged_data, aes(x=Event, y=mean_pupil, color=Event), width=0.1, alpha=0.5, size =5)+# Model-based predictions: points for Predicted valuesgeom_point(data=pred, aes(x=Event, y=Predicted, fill=Event), shape=21, size=10)+# Error bars for the confidence intervalsgeom_errorbar(data=pred, aes(x=Event, ymin=Predicted-SE, ymax=Predicted+SE, color=Event), width=0.2, lwd=1.5)+theme_bw(base_size =45)+theme(legend.position ='none')+labs(title="Predicted Means vs. Observed Data", x="Condition", y="Baseline-Corrected Pupil Size")
Analysing the time course of pupil size
Although we have seen how to compare mean values of pupil size, our original data was much richer. By taking averages, we made it simpler but we also lost precious information. Usually, it is better to keep the data as rich as possible, even if that might require more complex analyses. Here we’ll show you one example of a more complex analysis: generalised additive models. Fear not though!!! As usual, we will try to break it down in small digestible bites, and you might realise it’s not actually that complicated after all.
The key aspect here is that we will stop taking averages, and analyse the time course of pupil dilation instead. We will analyse how it changes over time with precision in the order of milliseconds!! This is exciting!!!
This is something that we cannot do with linear models. For example, in this case linear models would assume that, over the course of a trial, pupil size will only increase linearly over time. The model would be something like this:
linear_model=lmer(mean_pupil~Event*time+(1|Subject), data =data)
Note that, compared to the previous model, we have made two changes: First, we have changed the data. While before we were using averages, now we use the richer data set; Second, we added time as a predictor. We are saying that mean_pupil might be changing linearly across time… But this is very silly!!! To understand how silly it is, let’s have a look at the data over time.
Code
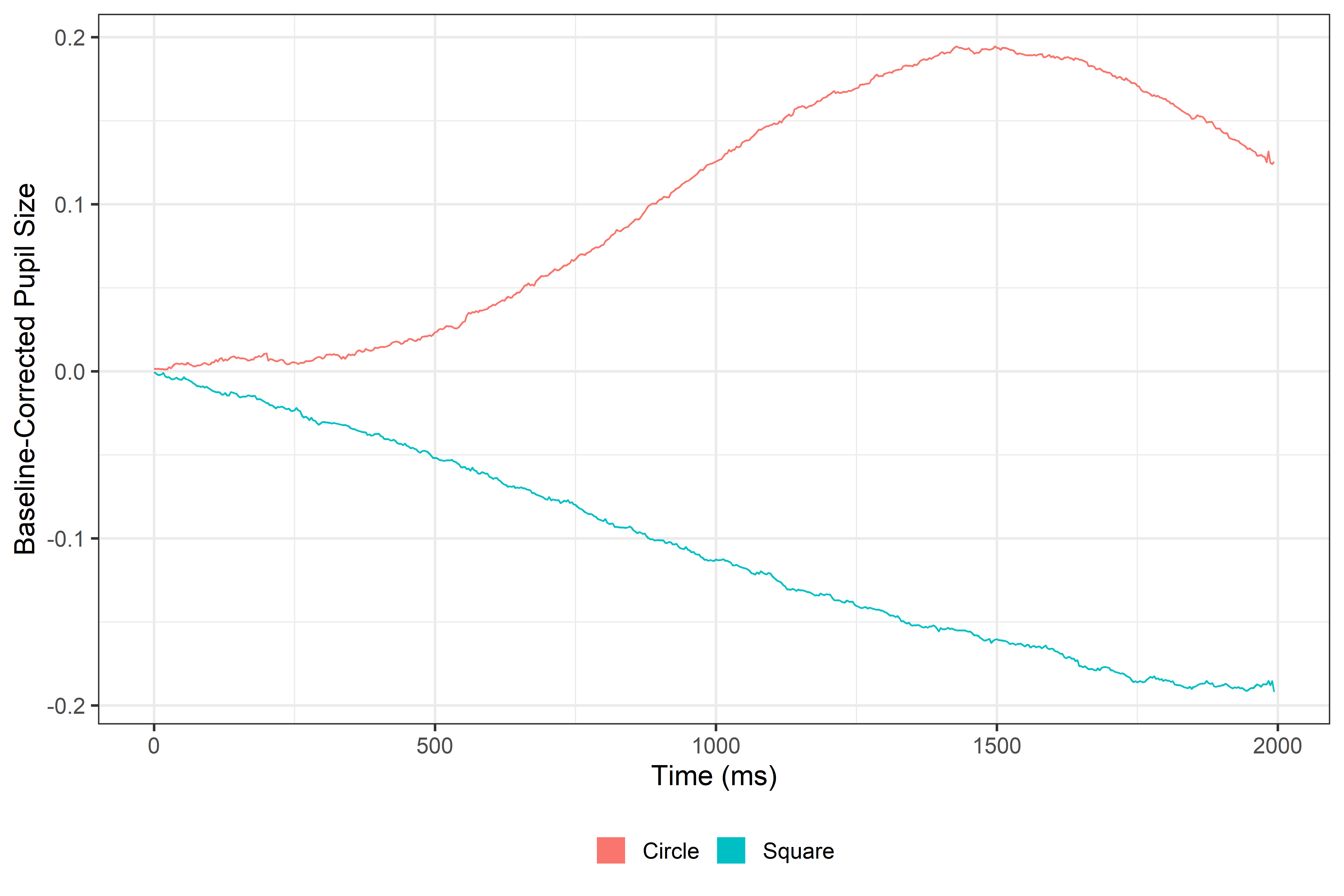
# Let's first compute average pupil size at each time point by conditiondata_avg_time=data%>%group_by(Event, time)%>%summarise(mean_pupil =mean(mean_pupil, na.rm=TRUE))# Now let's plot these averages over timeggplot(data_avg_time, aes(x=time, y=mean_pupil, color=Event))+geom_line(lwd=1.5)+theme_bw(base_size =45)+theme(legend.position ='bottom', legend.title =element_blank())+guides(color =guide_legend(override.aes =list(lwd =20)))+labs(x ="time (ms)", y ="Baseline-Corrected Pupil Size")
Here’s the data averaged by condition at each time point. As you can clearly see, pupil dilation doesn’t follow a simple linear increase or decrease; the pattern is much more complex. Let’s see how poorly a simple linear model fits this intricate pattern!
Code
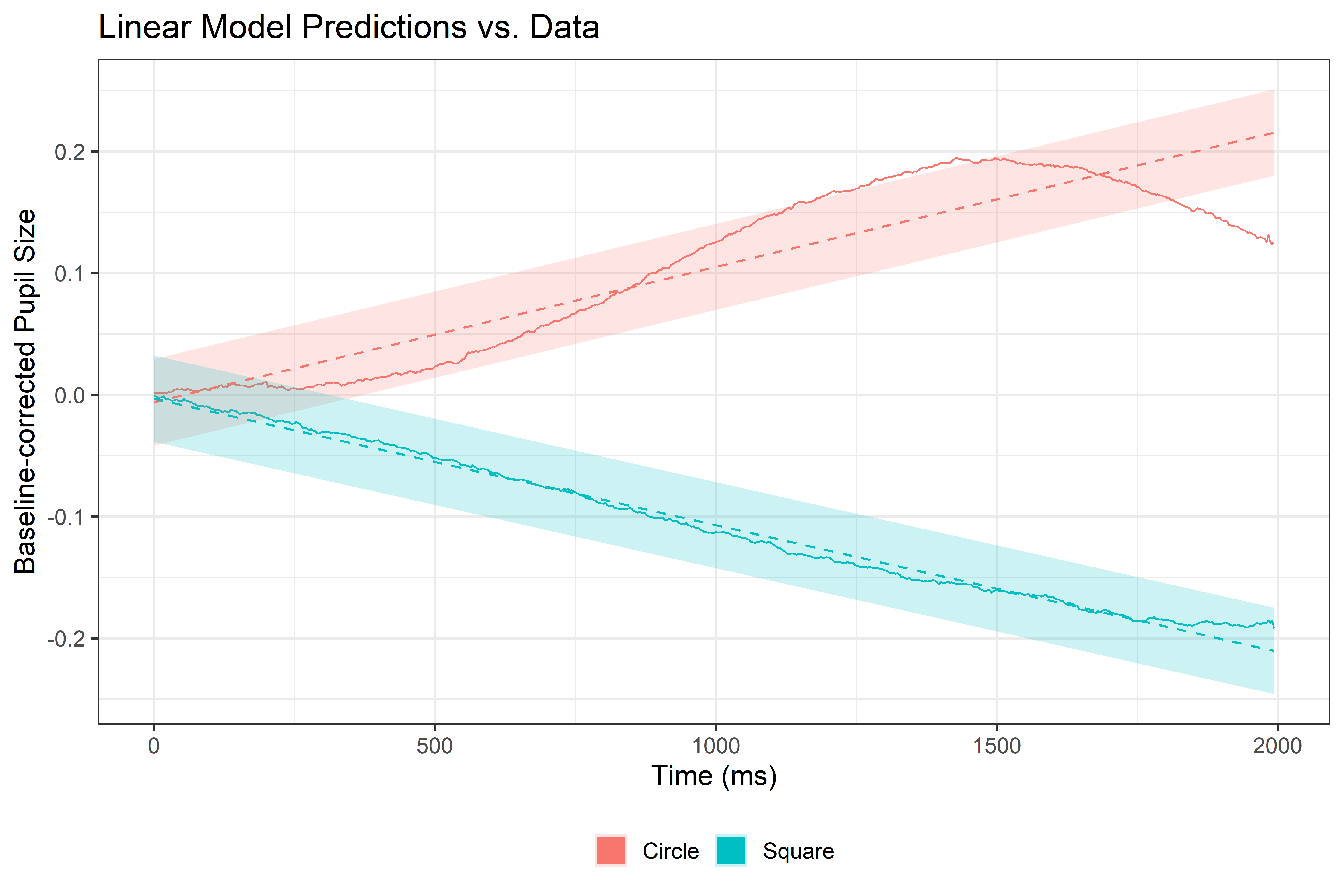
# Create a data grid for Event and timedatagrid=get_datagrid(linear_model, by =c('Event','time'))# Estimate expectation and uncertainty (Predicted and SE)Est=estimate_expectation(linear_model, datagrid)# Plot predictions with confidence intervals and the observed dataggplot()+# Real data linegeom_line(data =data_avg_time, aes(x=time, y=mean_pupil, color=Event), lwd=1.5)+# Predicted ribbonsgeom_ribbon(data =Est, aes(x=time, ymin =Predicted-SE, ymax =Predicted+SE, fill =Event), alpha =0.2)+# Predicted linesgeom_line(data =Est, aes(x=time, y=Predicted, color=Event), lwd=1.8,linetype ="dashed")+theme_bw(base_size =45)+theme(legend.position ='bottom', legend.title =element_blank())+guides(color =guide_legend(override.aes =list(lwd =20)))+labs(title ="Linear Model Predictions vs. Data", x ="time (ms)", y ="Baseline-corrected Pupil Size")
The estimates from our model don’t really resemble the actual data! To capture all those non-linear, smooth changes over time, we need a more sophisticated approach. Enter Generalized Additive Models (GAMs)—the perfect tool to save the day!
Generalized additive model
Here, we will not get into all the details of generalized additive models (from now on, GAMs). We will just show one example of how they can be used to model pupil size. To do this, we have to abandon linear models and download a new package instead, mgcv (install.packages("mgcv")). This package is similar to the one we used before for linear models but offers greater flexibility, particularly for modeling time-series data and capturing non-linear relationships.
What are GAMs
Ok, cool! GAMs sound awesome… but you might still be wondering what they actually do. Let me show you an example with some figures—that always helps make things clearer!
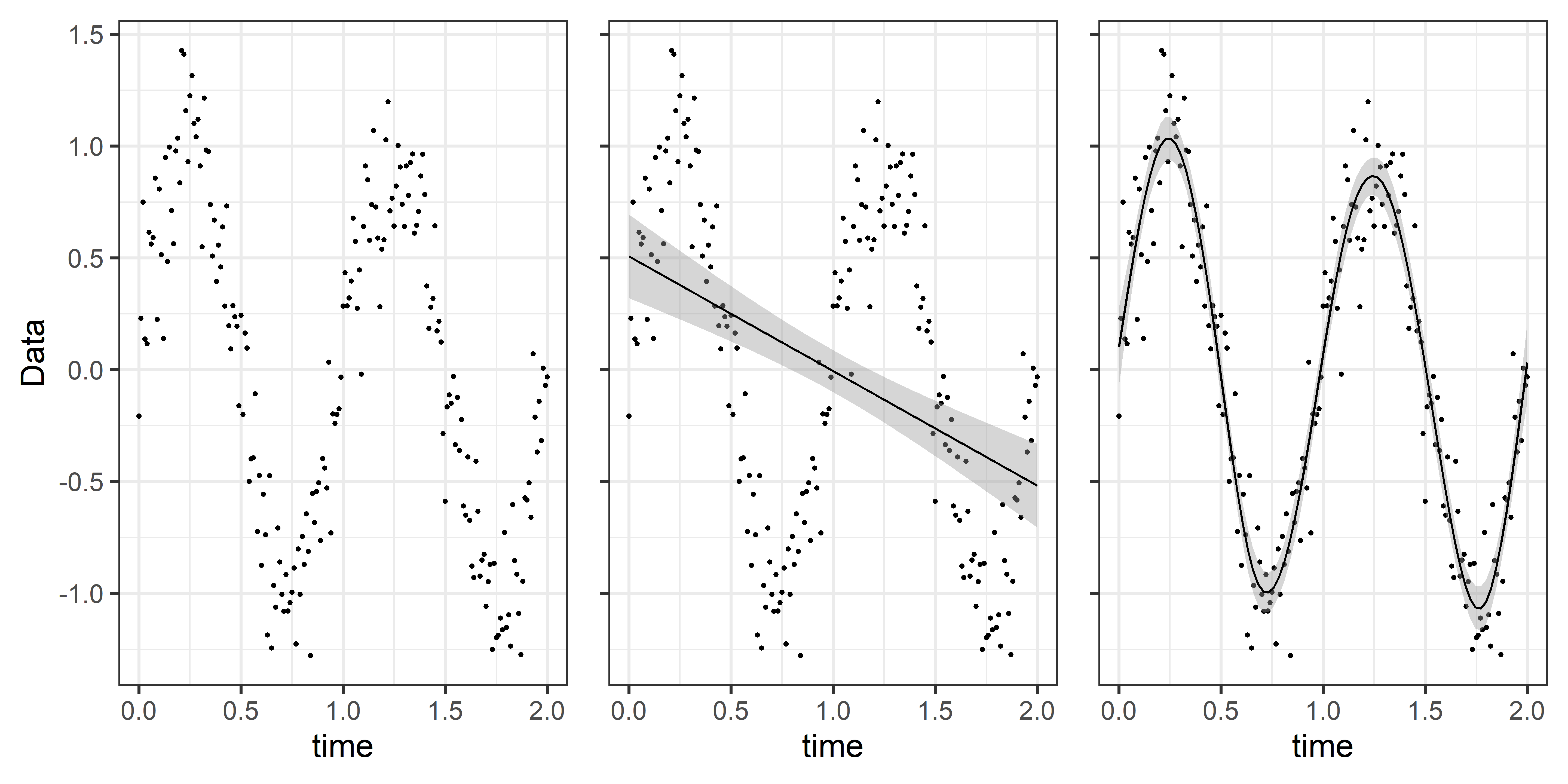
When modeling data with many fluctuations, a simple linear model often falls short. In the left plot, we see the raw data with its complex, non-linear pattern. The middle plot illustrates a linear model’s attempt to capture these fluctuations, but it oversimplifies the relationships and fails to reflect the true data structure. Finally, the right plot showcases an additive model, which adapts to the data’s variability by following its fluctuations and accurately capturing the underlying pattern. This demonstrates the strength of additive models in modeling non-linear, smooth changes.
Well….. This sounds like the same problem we have in our pupil data!!! Let’s go figure
Note
Linear models can be extended to capture fluctuations using polynomial terms, but this approach has limitations. Higher-order polynomials can overfit the data, capturing noise instead of meaningful patterns. Additive models, however, use smooth functions like splines to flexibly adapt to data fluctuations without the instability of polynomials, making them a more robust and interpretable choice.
Run our GAM
To run a GAM, the syntax is relatively similar to what we used in the linear model section.
mean_pupil ~ Event: Here, I treat Condition as a main effect, just like we did before.
s(time, by=Event, k=20): This is where the magic happens. By wrapping time in s(), we are telling the model: “Don’t assume that changes in pupil size over time are linear. Instead, estimate a smooth, wiggly function.” The argument by=Event means: “Do this separately for each condition, so that each condition gets its own smooth curve over time.” Finally, k=20 controls how wiggly the curve can be (technically, how many ‘knots’ or flexibility points the smoothing function is allowed to have). In practice, we are allowing the model to capture complex, non-linear patterns of pupil size changes over time for each condition.
s(time, Subject, bs='fs', m=1): Here, we go one step further and acknowledge that each participant might have their own unique shape of the time course. By using bs='fs', I am specifying a ‘factor smooth’, which means: “For each subject, estimate their own smooth function over time.” Setting m=1 is a specific parameter choice that defines how we penalize wiggliness. Essentially, this term is allowing us to capture individual differences in how pupil size changes over time, over and above the general pattern captured by the main smooth. It’s something like the random effect we have seen before in the linear mixed-effect model.
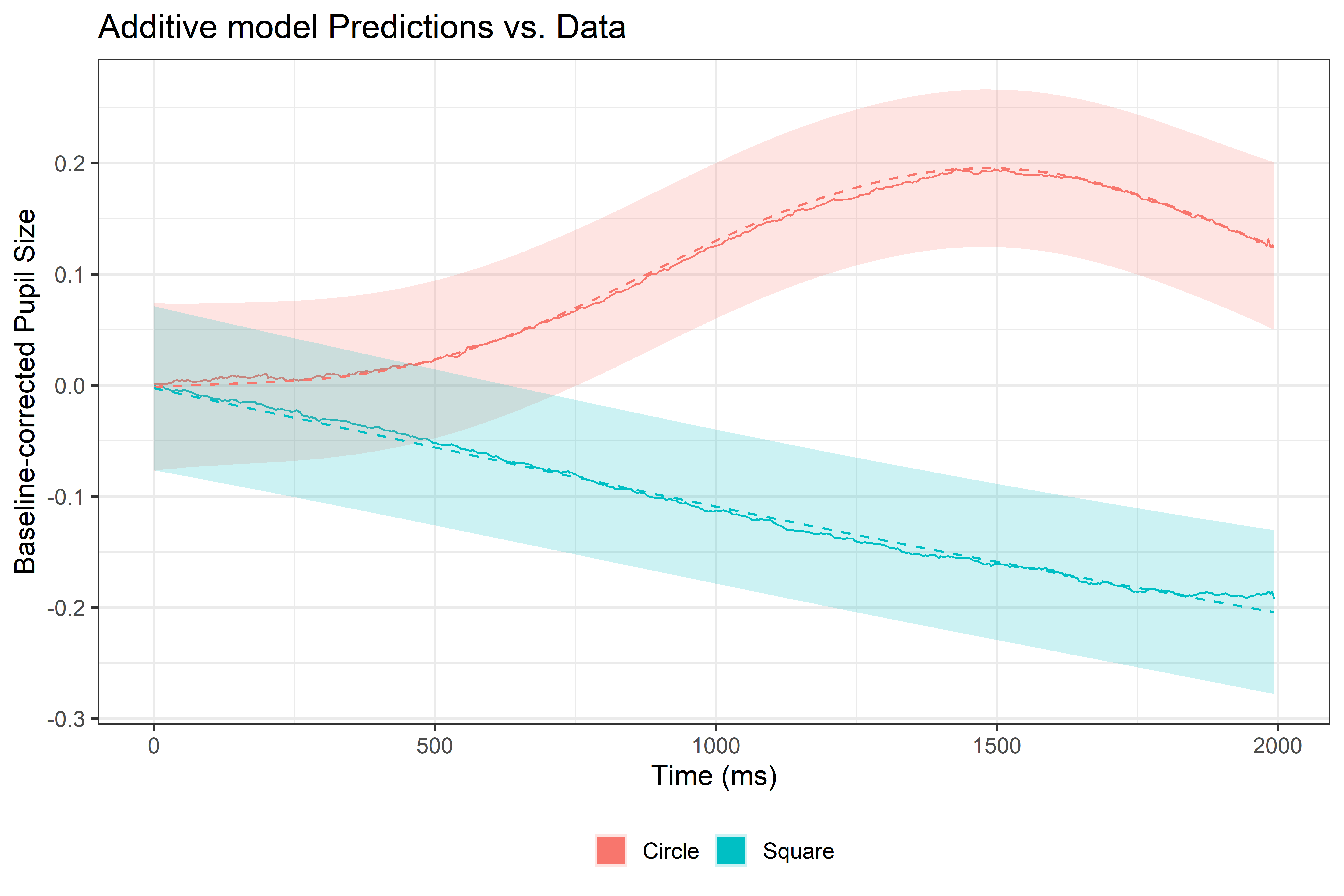
Now that we have run our first GAM, we can see how well it predicts the data!
Code
# Data griddatagrid=get_datagrid(additive_model, length =100, include_random =T)# Estimate expectation and uncertainty (Predicted and SE)Est=estimate_expectation(additive_model, datagrid, exclude=c("s(time,Subject)"))# Plot predictions with confidence intervals and the observed dataggplot()+# Real data linegeom_line(data =data_avg_time, aes(x=time, y=mean_pupil, color=Event), size=1.5)+# Predicted ribbonsgeom_ribbon(data =Est, aes(x=time, ymin =CI_low, ymax =CI_high, fill =Event), alpha =0.2)+# Predicted linesgeom_line(data =Est, aes(x=time, y=Predicted, color=Event), size=1.8, linetype ="dashed")+theme_bw(base_size =45)+theme(legend.position ='bottom', legend.title =element_blank())+guides(color =guide_legend(override.aes =list(lwd =20)))+labs(title ="Additive model Predictions vs. Data", x ="time (ms)", y ="Baseline-corrected Pupil Size")
This looks so much better!!! The line fit so much better to the data!! We can also have a look at whether the effect of our experimental condition is significant:
The fixed effects (Parametric coefficients) show a strong negative effect for Eventquare, indicating that pupil size for Square is significantly lower than for Circle. This suggests that pupil size is greater when expecting a rewarding stimulus compared to a non-rewarding one.
The smooth terms indicate whether the non-linear relationships modeled by s() explain significant variance in the data. A significant smooth term confirms that the function captures meaningful, non-linear patterns beyond random noise or simpler terms. While fixed effects are typically more important for hypothesis testing, it’s crucial to ensure the model specification captures the data’s fluctuations accurately.
You did it!!! You started from a simpler model and little by little you built a very complex Generalized Additive Model!! Amazing work!!!
Warning
This is just a very basic tutorial!
There are additional checks and considerations to keep in mind when using additive models to model pupil dilation data. We plan to extend this tutorial over time to include more details.
Luckily, there are researchers who have already explored and explained these steps thoroughly. This paper, in particular, has greatly informed our approach. It dives deeper into the use of GAMs (still with the mgcv package), reviewing techniques for fitting models, addressing auto-correlations, and ensuring the accuracy and robustness of your GAMs. We highly recommend reading this paper to deepen your understanding!
---title: "Pupil Data Analysis"date: "01/02/2025"author-meta: Francesco Polidescription-meta: "Learn how to analyse pupil data, from a simple linear model to generalised additive models"keywords-meta: "R, pupillometry, gam, additive models, statistics, analysis, psychology, tutorial, experiment, DevStart, developmental science"categories: - Stats - R - Modelling - Additive modelslightbox: true---If you have collected and pre-processed your pupil data, the long awaited moment arrived: It's finally time to analyse your data and get your results!!!In this tutorial we will do two types of analysis. The first one is more simple, and the second is more advanced. For some research questions, simple analyses are enough: they are intuitive and easy to understand. However, pupil data is actually very rich and complex, and more sophisticated analyses can sometimes help to really get the most out of your data and let them shine!::: callout-noteWe’re currently working on a tutorial about linear mixed-effect models, but it’s not ready yet! If you’re new to statistical analyses, we highly recommend this tutorial: [Introduction to linear mixed models](https://ourcodingclub.github.io/tutorials/mixed-models/). While it doesn’t focus on pupil data specifically, it covers all the essential basics that won’t be addressed here and can be incredibly helpful.:::Before starting any type of analysis, let's import the data and take a quick look at it.## Import dataThe data used in this tutorial comes from the pre-processing tutorial of pupil dilation. If you haven’t run that tutorial yet, it’s a good idea to check it out first to ensure your data is prepared and ready for analysis: [Pre-processing pupil data](PupilPreprocessing.qmd). In case you did not save the result of the pre-processing you can download them from here :{{< downloadthis ../../resources/Pupillometry/Processed/Processed_PupilData.csv label="Preprocessed_PupilData.csv" type="secondary" >}}Now that you have the data, let's import it along with the necessary libraries. We'll also ensure that the `Event` and `Subjects` columns are properly set as factors (categorical for easier analysis. Here's how:```{r}#| message: false#| warning: falselibrary(tidyverse) # Data manipulation and visualizationlibrary(easystats) # Easy statistical modelingdata =read.csv("..\\..\\resources\\Pupillometry\\Processed\\Processed_PupilData.csv")# Make sure Event and Subject are factorsdata$Event =as.factor(data$Event)data$Subject =as.factor(data$Subject)head(data)```For a detailed description of the data, you can have a look at the tutorial on [preprocessing pupil data](PupilPreprocessing.qmd). The key variables to focus on here are the following:- `mean_pupil` indicates what the pupil size was at every moment in time (every 50 milliseconds, 20Hz). This is our dependent variable.- `time` indicates the specific moment in time within each trial- `TrialN` indicates the trial number- `Event` indicates whether the trial contained a circle (followed by a reward) or a square (not followed by a reward). This variable is not numerical, but categorical. We thus set it to factor with `as.factor()`.- `Subject` contains a different ID number for each subject. This is also a categorical variable.## Comparing meansIn many paradigms, you have two or more conditions and want to test whether your dependent variable (pupil size in this case!) is significantly different across conditions. In [our example paradigm](..\GettingStarted\CreateYourFirstParadigm.qmd), we may want to test whether, on average, pupil size while looking at the rewarding cue (the circle) is greater than pupil size while looking at the non-rewarding cue (the square). This would mean that even before the reward is presented, infants have learned that a reward will be coming and dilate their pupils in response to it! Pretty cool, uh?If we want to test multiple groups, we can use a t-test, an ANOVA or... A linear model! Here, we'll be using a special type of linear model, a mixed-effect model - which is infinitely better for many many reasons \[add link\].### Adapt the dataWe want to compare the means across conditions but... We don't have means yet! We have a much richer dataset, that contains hundreds of datapoints with milliseconds precision. For this first simple analysis, we just want one average measure of pupil dilation for each trial instead. We can compute this using the `tidyverse` library (that is container of multiple packages) a powerful collection of packages for wrangling and visualuzating dataframes in R.Here, we group the data by Subject, Event, and TrialN, then summarize it within these groups by calculating the mean values.```{r}#| message: false#| warning: falseaveraged_data = data %>%group_by(Subject, Event, TrialN) %>%summarise(mean_pupil =mean(mean_pupil, na.rm =TRUE))head(averaged_data)```::: callout-importantIn this step, we used the **average** to calculate an index for each trial, meaning we averaged the pupil dilation over the trial duration. However, this is not the only option. Other approaches include extracting the **peak** value (`max(mean_pupil, na.rm = TRUE)`) or calculating the **sum** of the signal (`sum(mean_pupil, na.rm = TRUE)`), which can also represent the **area under the curve (AUC)** for the trial.:::### Linear mixed-effects modelWith a single value for each participant, condition, and trial (averaged across time points), we are now ready to proceed with our analysis. Even if the word "Linear mixed-effect model" might sound scary, the model is actually very simple. We take our experimental conditions (Event) and check whether they affect pupil size (mean_pupil). To account for individual differences in pupil response intensity, we include participants as a random intercept.Let's give it a go!!!```{r}#| message: false#| warning: falselibrary(lmerTest) # Mixed-effect models library# The actual modelmodel_avg =lmer(mean_pupil ~ Event + (1|Subject), data = averaged_data)summary(model_avg) # summary of the model```::: callout-tipWe won’t dive into the detailed interpretation of the results here—this isn’t the right place for that. However, if you are not familiar with linear mixed-effects models you can check our introduction of [Linear models](..\Stats\LinearModels.qmd) and [Linear mixed-effects models](..\Stats\LinearMixedModels.qmd) where we try to break everything down step by step!:::The key takeaway here is that there’s a significatn difference between the **Event**. Specifically, the **Square** cue appears to result in smaller pupil dilation compared to the **Circle** event (which serves as the reference level for the intercept). **COOL!**Let’s visualize the effect!!```{r}#| message: false#| warning: false#| code-fold: true#| fig-align: center#| fig-height: 20#| fig-width: 30# Create a data grid for Event and timedatagrid =get_datagrid(model_avg, by =c('Event'))# Compute model-based expected values for each level of Eventpred =estimate_expectation(datagrid)# 'pred' now contains predicted values and confidence intervals for each event condition.# We can visualize these predictions and overlay them on the observed data.ggplot() +# Observed data (jittered points to show distribution)geom_jitter(data = averaged_data, aes(x=Event, y=mean_pupil, color=Event), width=0.1, alpha=0.5, size =5) +# Model-based predictions: points for Predicted valuesgeom_point(data=pred, aes(x=Event, y=Predicted, fill=Event), shape=21, size=10) +# Error bars for the confidence intervalsgeom_errorbar(data=pred, aes(x=Event, ymin=Predicted - SE, ymax=Predicted + SE, color=Event), width=0.2, lwd=1.5) +theme_bw(base_size =45)+theme(legend.position ='none') +labs(title="Predicted Means vs. Observed Data",x="Condition",y="Baseline-Corrected Pupil Size")```## Analysing the time course of pupil sizeAlthough we have seen how to compare mean values of pupil size, our original data was much richer. By taking averages, we made it simpler but we also lost precious information. Usually, it is better to keep the data as rich as possible, even if that might require more complex analyses. Here we'll show you one example of a more complex analysis: generalised additive models. Fear not though!!! As usual, we will try to break it down in small digestible bites, and you might realise it's not actually that complicated after all.The key aspect here is that we will stop taking averages, and analyse the time course of pupil dilation instead. We will analyse how it changes over time with precision in the order of milliseconds!! This is exciting!!!This is something that we cannot do with linear models. For example, in this case linear models would assume that, over the course of a trial, pupil size will only increase *linearly* over time. The model would be something like this:```{r}#| message: false#| warning: falselinear_model =lmer(mean_pupil ~ Event * time + (1|Subject), data = data) ```Note that, compared to the previous model, we have made two changes: First, we have changed the data. While before we were using averages, now we use the richer data set; Second, we added time as a predictor. We are saying that mean_pupil might be changing *linearly* across time... But this is very silly!!! To understand how silly it is, let's have a look at the data over time.```{r}#| message: false#| warning: false#| code-fold: true#| fig-align: center#| fig-height: 20#| fig-width: 30# Let's first compute average pupil size at each time point by conditiondata_avg_time = data %>%group_by(Event, time) %>%summarise(mean_pupil =mean(mean_pupil, na.rm=TRUE))# Now let's plot these averages over timeggplot(data_avg_time, aes(x=time, y=mean_pupil, color=Event)) +geom_line(lwd=1.5) +theme_bw(base_size =45)+theme(legend.position ='bottom',legend.title =element_blank()) +guides(color =guide_legend(override.aes =list(lwd =20))) +labs(x ="time (ms)",y ="Baseline-Corrected Pupil Size") ```Here’s the data averaged by condition at each time point. As you can clearly see, pupil dilation doesn’t follow a simple linear increase or decrease; the pattern is much more complex. Let’s see how poorly a simple linear model fits this intricate pattern!```{r}#| message: false#| warning: false#| code-fold: true#| fig-height: 20#| fig-width: 30# Create a data grid for Event and timedatagrid =get_datagrid(linear_model, by =c('Event','time'))# Estimate expectation and uncertainty (Predicted and SE)Est =estimate_expectation(linear_model, datagrid)# Plot predictions with confidence intervals and the observed dataggplot() +# Real data linegeom_line(data = data_avg_time, aes(x=time, y=mean_pupil, color=Event), lwd=1.5) +# Predicted ribbonsgeom_ribbon(data = Est, aes(x=time, ymin = Predicted - SE, ymax = Predicted + SE,fill = Event), alpha =0.2) +# Predicted linesgeom_line(data = Est, aes(x=time, y=Predicted, color=Event), lwd=1.8,linetype ="dashed") +theme_bw(base_size =45)+theme(legend.position ='bottom',legend.title =element_blank()) +guides(color =guide_legend(override.aes =list(lwd =20))) +labs(title ="Linear Model Predictions vs. Data",x ="time (ms)",y ="Baseline-corrected Pupil Size")```The estimates from our model don’t really resemble the actual data! To capture all those non-linear, smooth changes over time, we need a more sophisticated approach. Enter **Generalized Additive Models (GAMs)**—the perfect tool to save the day!### Generalized additive modelHere, we will not get into all the details of generalized additive models (from now on, GAMs). We will just show one example of how they can be used to model pupil size. To do this, we have to abandon linear models and download a new package instead, mgcv (`install.packages("mgcv")`). This package is similar to the one we used before for linear models but offers greater flexibility, particularly for modeling time-series data and capturing non-linear relationships.#### What are GAMsOk, cool! GAMs sound awesome... but you might still be wondering what they actually do. Let me show you an example with some figures—that always helps make things clearer!```{r}#| message: false#| warning: false#| code-fold: true#| fig-height: 15#| fig-width: 30library(patchwork)# Parametersamp <-1; freq <-1; phase <-0; rate <-100; dur <-2time <-seq(0, dur, by =1/ rate)# Sinusoidal wave with noisewave <- amp *sin(2* pi * freq * time + phase) +rnorm(length(time), mean =0, sd =0.2)# Plotone =ggplot()+geom_point(aes(y=wave, x= time),size=3)+theme_bw(base_size =45)+labs(y='Data')two =ggplot()+geom_point(aes(y=wave, x= time),size=3)+geom_smooth(aes(y=wave, x= time), method ='lm', color='black', lwd=1.5)+theme_bw(base_size =45)+theme(axis.title.y =element_blank(),axis.text.y =element_blank() )tree=ggplot()+geom_point(aes(y=wave, x= time),size=3)+geom_smooth(aes(y=wave, x= time), method ='gam', color='black', lwd=1.5)+theme_bw(base_size =45)+theme(axis.title.y =element_blank(),axis.text.y =element_blank() )one + two + tree```When modeling data with many fluctuations, a simple linear model often falls short. In the left plot, we see the raw data with its complex, non-linear pattern. The middle plot illustrates a linear model’s attempt to capture these fluctuations, but it oversimplifies the relationships and fails to reflect the true data structure. Finally, the right plot showcases an additive model, which adapts to the data’s variability by following its fluctuations and accurately capturing the underlying pattern. This demonstrates the strength of additive models in modeling non-linear, smooth changes.**Well..... This sounds like the same problem we have in our pupil data!!! Let's go figure**::: callout-noteLinear models can be extended to capture fluctuations using polynomial terms, but this approach has limitations. Higher-order polynomials can overfit the data, capturing noise instead of meaningful patterns. Additive models, however, use smooth functions like splines to flexibly adapt to data fluctuations without the instability of polynomials, making them a more robust and interpretable choice.:::### Run our GAMTo run a GAM, the syntax is relatively similar to what we used in the linear model section.```{r}#| message: false#| warning: falselibrary("mgcv")# Additive modeladditive_model =bam(mean_pupil ~ Event+s(time, by=Event, k=20)+s(time, Subject, bs='fs', m=1),data=data)```Let's break the formula down:- `mean_pupil ~ Event`: Here, I treat Condition as a main effect, just like we did before.- `s(time, by=Event, k=20)`: This is where the magic happens. By wrapping `time` in `s()`, we are telling the model: “*Don’t assume that changes in pupil size over time are linear. Instead, estimate a smooth, wiggly function.*” The argument `by=Event` means: “*Do this separately for each condition, so that each condition gets its own smooth curve over time.*” Finally, `k=20` controls how wiggly the curve can be (technically, how many ‘knots’ or flexibility points the smoothing function is allowed to have). In practice, we are allowing the model to capture complex, non-linear patterns of pupil size changes over time for each condition.- `s(time, Subject, bs='fs', m=1)`: Here, we go one step further and acknowledge that each participant might have their own unique shape of the time course. By using `bs='fs'`, I am specifying a ‘factor smooth’, which means: “*For each subject, estimate their own smooth function over time.*” Setting `m=1` is a specific parameter choice that defines how we penalize wiggliness. Essentially, this term is allowing us to capture individual differences in how pupil size changes over time, over and above the general pattern captured by the main smooth. It's something like the random effect we have seen before in the linear mixed-effect model.Now that we have run our first GAM, we can see how well it predicts the data!```{r}#| message: false#| warning: false#| code-fold: true#| fig-height: 20#| fig-width: 30# Data griddatagrid =get_datagrid(additive_model, length =100, include_random = T)# Estimate expectation and uncertainty (Predicted and SE)Est =estimate_expectation(additive_model, datagrid, exclude=c("s(time,Subject)"))# Plot predictions with confidence intervals and the observed dataggplot() +# Real data linegeom_line(data = data_avg_time, aes(x=time, y=mean_pupil, color=Event), size=1.5) +# Predicted ribbonsgeom_ribbon(data = Est, aes(x=time, ymin = CI_low, ymax = CI_high,fill = Event), alpha =0.2) +# Predicted linesgeom_line(data = Est, aes(x=time, y=Predicted, color=Event), size=1.8, linetype ="dashed") +theme_bw(base_size =45)+theme(legend.position ='bottom',legend.title =element_blank()) +guides(color =guide_legend(override.aes =list(lwd =20))) +labs(title ="Additive model Predictions vs. Data",x ="time (ms)",y ="Baseline-corrected Pupil Size")```This looks so much better!!! The line fit so much better to the data!! We can also have a look at whether the effect of our experimental condition is significant:```{r}#| message: false#| warning: falsesummary(additive_model) ```The fixed effects (*Parametric coefficients*) show a strong negative effect for `Eventquare`, indicating that pupil size for Square is significantly lower than for Circle. This suggests that pupil size is greater when expecting a rewarding stimulus compared to a non-rewarding one.The smooth terms indicate whether the non-linear relationships modeled by s() explain significant variance in the data. A significant smooth term confirms that the function captures meaningful, non-linear patterns beyond random noise or simpler terms. While fixed effects are typically more important for hypothesis testing, it’s crucial to ensure the model specification captures the data's fluctuations accurately.You did it!!! You started from a simpler model and little by little you built a very complex Generalized Additive Model!! Amazing work!!!::: callout-warning**This is just a very basic tutorial!**There are additional checks and considerations to keep in mind when using additive models to model pupil dilation data. We plan to extend this tutorial over time to include more details.Luckily, there are researchers who have already explored and explained these steps thoroughly. [This paper](https://journals.sagepub.com/doi/10.1177/2331216519832483), in particular, has greatly informed our approach. It dives deeper into the use of GAMs (still with the **mgcv** package), reviewing techniques for fitting models, addressing auto-correlations, and ensuring the accuracy and robustness of your GAMs. We highly recommend reading this paper to deepen your understanding!:::